Search K
Appearance
网络模型 前向传播,完成之后,的输出值,还要做一下损失计算,然后为了找到一个更好的模型,所以再反向传播(更新参数,找到性能更好的参数) ,通过损失来求 损失函数 梯度下降 网络训练过程
卷积核 cnn 对图像分类特别重要,它的网络结构 网络结构
假设输入层输入的是一堆水果(图片),经过中途这些流水线,输出层则是一杯水果茶(分类概率)
# 假设 testModel 是一个自定义的模型类
model = testModel()
# 创建一个 5x5 的二维矩阵
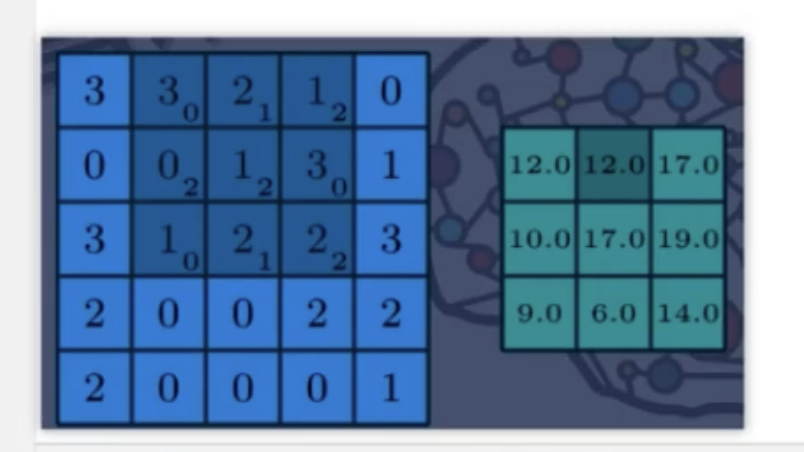
input = torch.tensor([
[3, 3, 2, 1, 0],
[2, 3, 2, 1, 0],
[3, 3, 2, 1, 0],
[4, 3, 2, 1, 0],
[1, 3, 2, 1, 0],
],dytype=torch.float)
# 使用 torch.reshape 将 input 张量的形状调整为 (1, 1, 5, 5)
# 我们想喂养到模型里面,但是它必须得4维才可以,所以通过reshape改变一下维度,前面两个1: (1, 1, 5, 5) 来占一下位置
input = torch.reshape(input, (1, 1, 5, 5))
# 将输入传递给模型进行前向传播,将分类概率进行一个输出
output = model(input)
# 打印输出张量
print(output)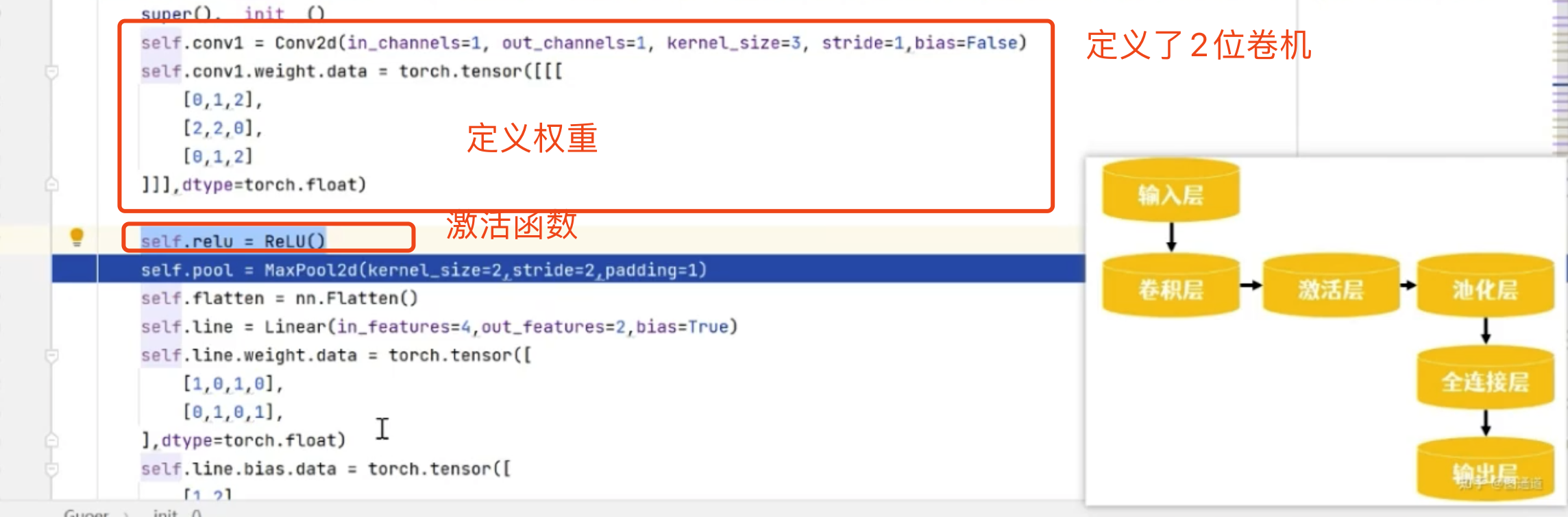
import torch
import torch.nn as nn
# 定义一个二维卷积层
self.conv1 = nn.Conv2d(
in_channels=1, # 输入通道数:1表示单通道(灰度图像),因为这张图是5*5*1的,所以通道数是1
out_channels=1, # 输出通道数:1表示输出一个通道, 因为我们只用1个滤波器扫这张图片,所以这个输出通道数也是1
kernel_size=3, # 卷积核的大小:3x3的卷积核 , 因为我们是用一个3*3的 来扫描左边的图,所以这个卷积核是3
stride=1, # 步长:默认为1, 每次只让它移动1格
padding=0, # 填充:0表示没有填充
dilation=1, # 膨胀:默认为1
groups=1, # 分组卷积:默认为1
bias=False # 是否使用偏置:False表示不使用偏置, 就是没有b
)
self.conv1.weight.data = torch.tensor([[[
[0,1,2],
[2,2,0],
[0,1,2],
]]])
self.relu= torch.nn.ReLU() # 定义了激活层的非线性激活函数
self.pool = torch.nn.MaxPool2d( kernel_size=2,stride=2, padding=1) # 最大池化
self.flatten=torch.nn.Flatten() # 展平
# 打印卷积层的定义
print(conv_layer)全连接层对特征进行整合,然后归一化,并对分类情况输出概率,在全连接层之前一般有一个扁平化操作
python 是语言环境 用到的计算基本都是 numpy 用到的数据分析的事基本都是 pandas 用到图形化可视化的时候用 matplotlib 解决深度学习问题的时候用 pytorch 解决机器学习问题的时候可以用 scikit learn
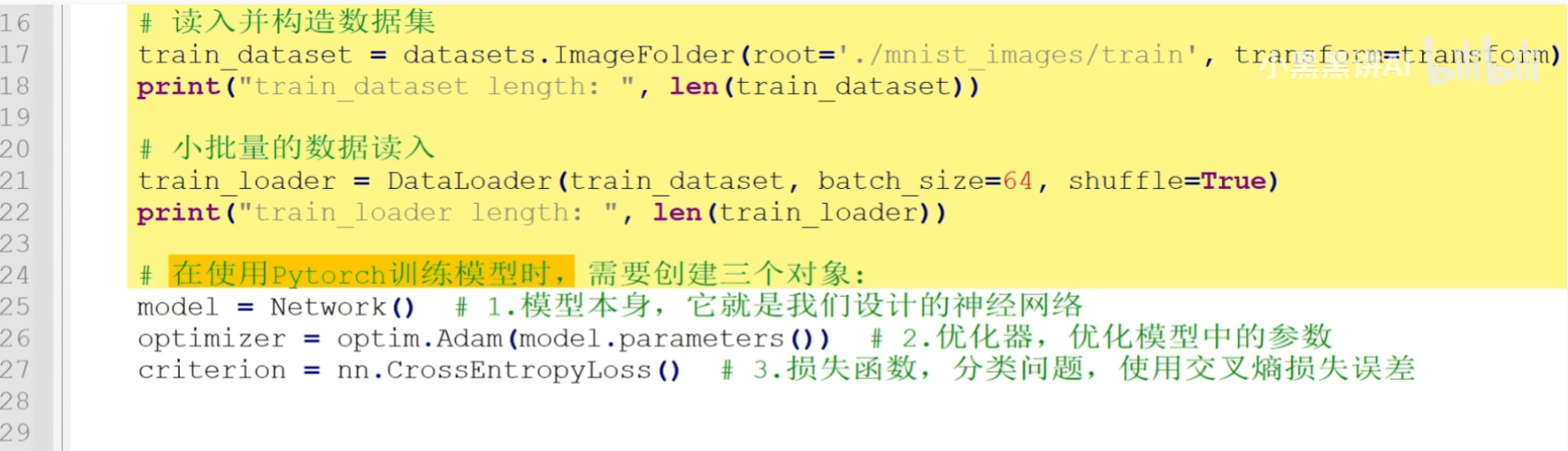
模型、损失函数、图片和标签
梯度清0后,才能进行反向传播
cnn-explainer
**
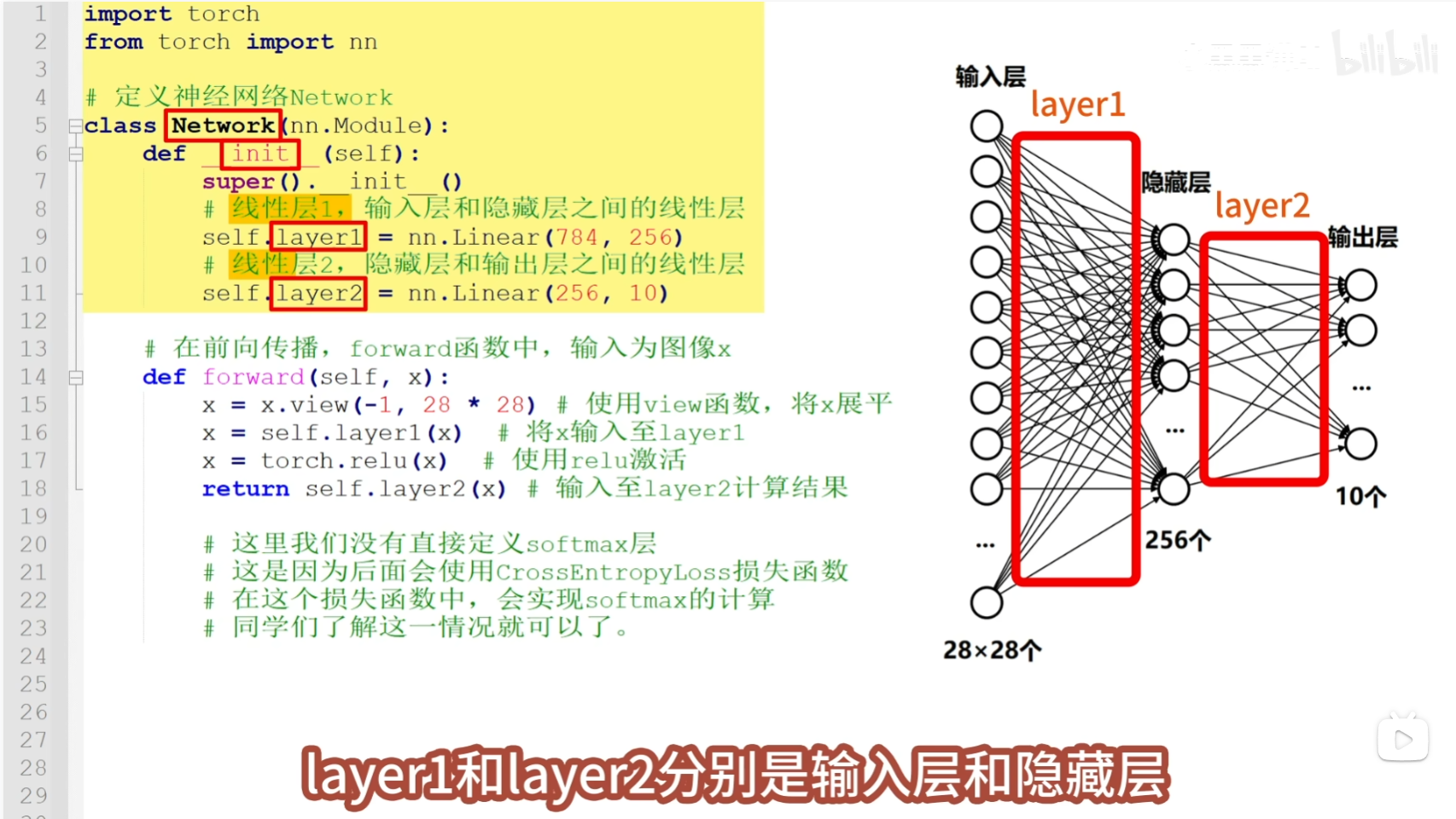
目前使用三层神经网络结构 tips:之所以叫隐藏层,是因为里面的过程太复杂,没法知道具体怎么运作的 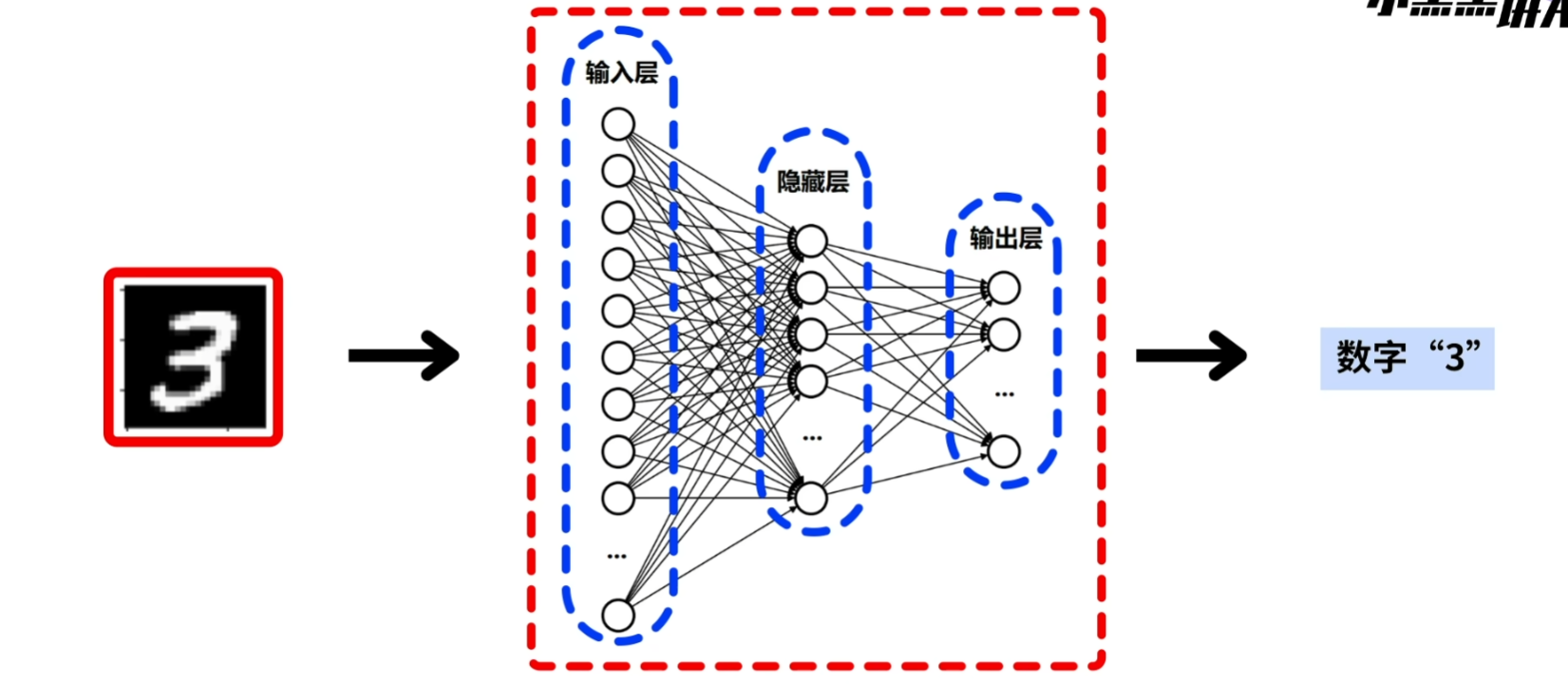
重点讲解
这个神经网络结构图展示了:
每一层的节点都与下一层的所有节点相连,形成全连接网络。这种结构能够:
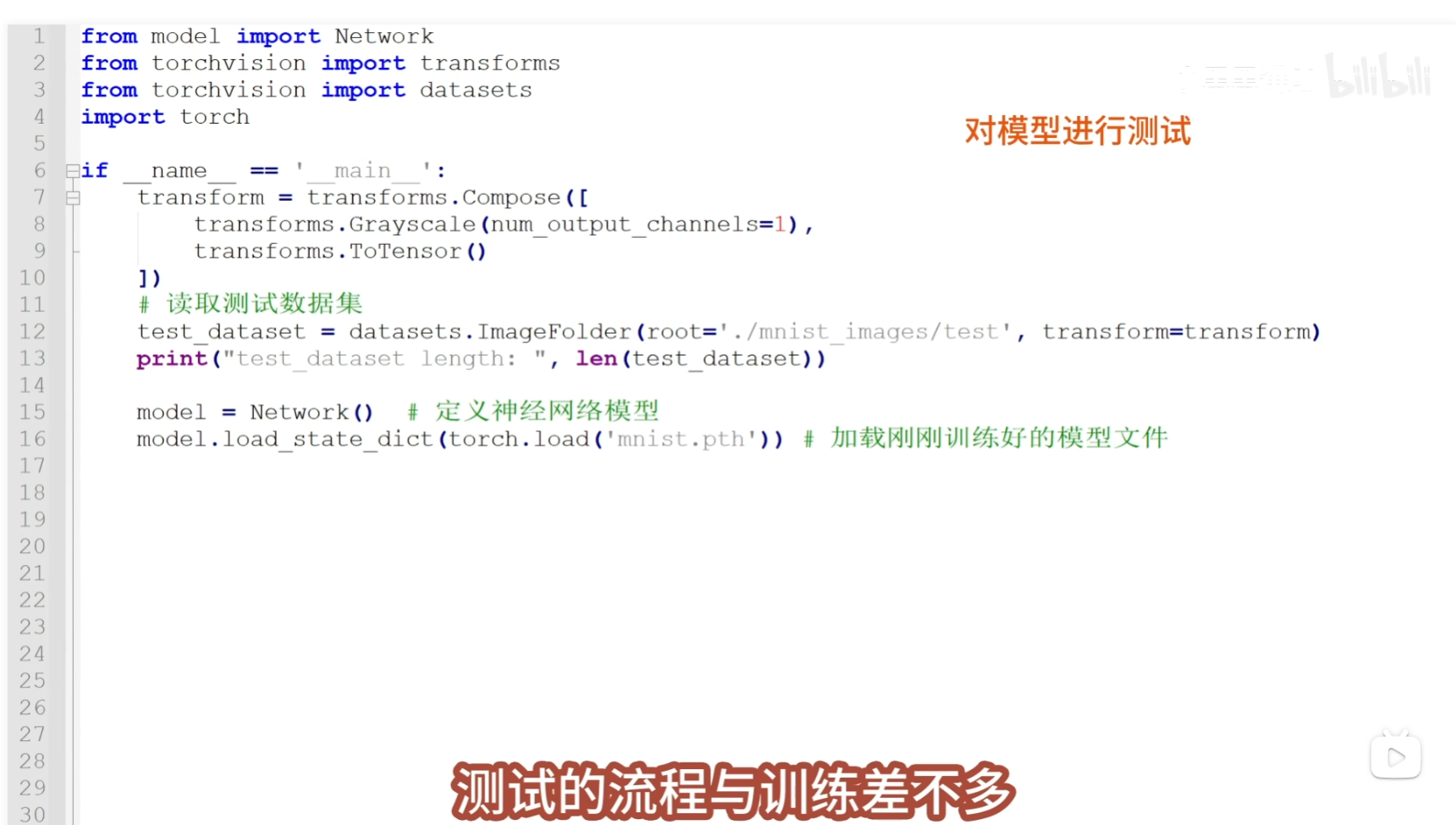
 设计处理一个处理图像的神经网络 需要首先明确输入的图像数据大小和格式, 我们处理的图片是2828像素的灰色通道图像,
设计处理一个处理图像的神经网络 需要首先明确输入的图像数据大小和格式, 我们处理的图片是2828像素的灰色通道图像, 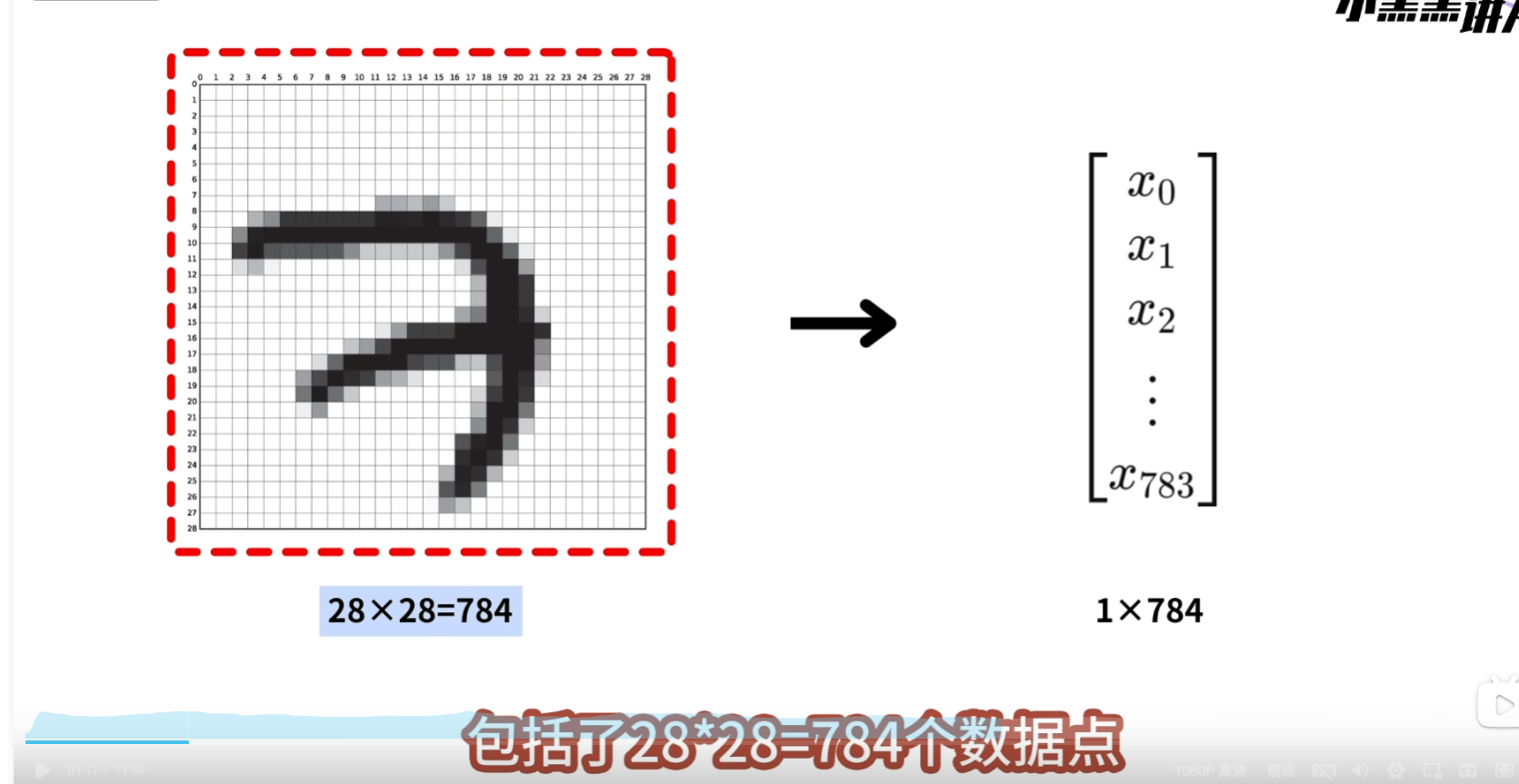 这样的图像包括了2828=784个像素点,我们要将它展平为1784的向量,然后再将这个向量输入到神经网络中
这样的图像包括了2828=784个像素点,我们要将它展平为1784的向量,然后再将这个向量输入到神经网络中 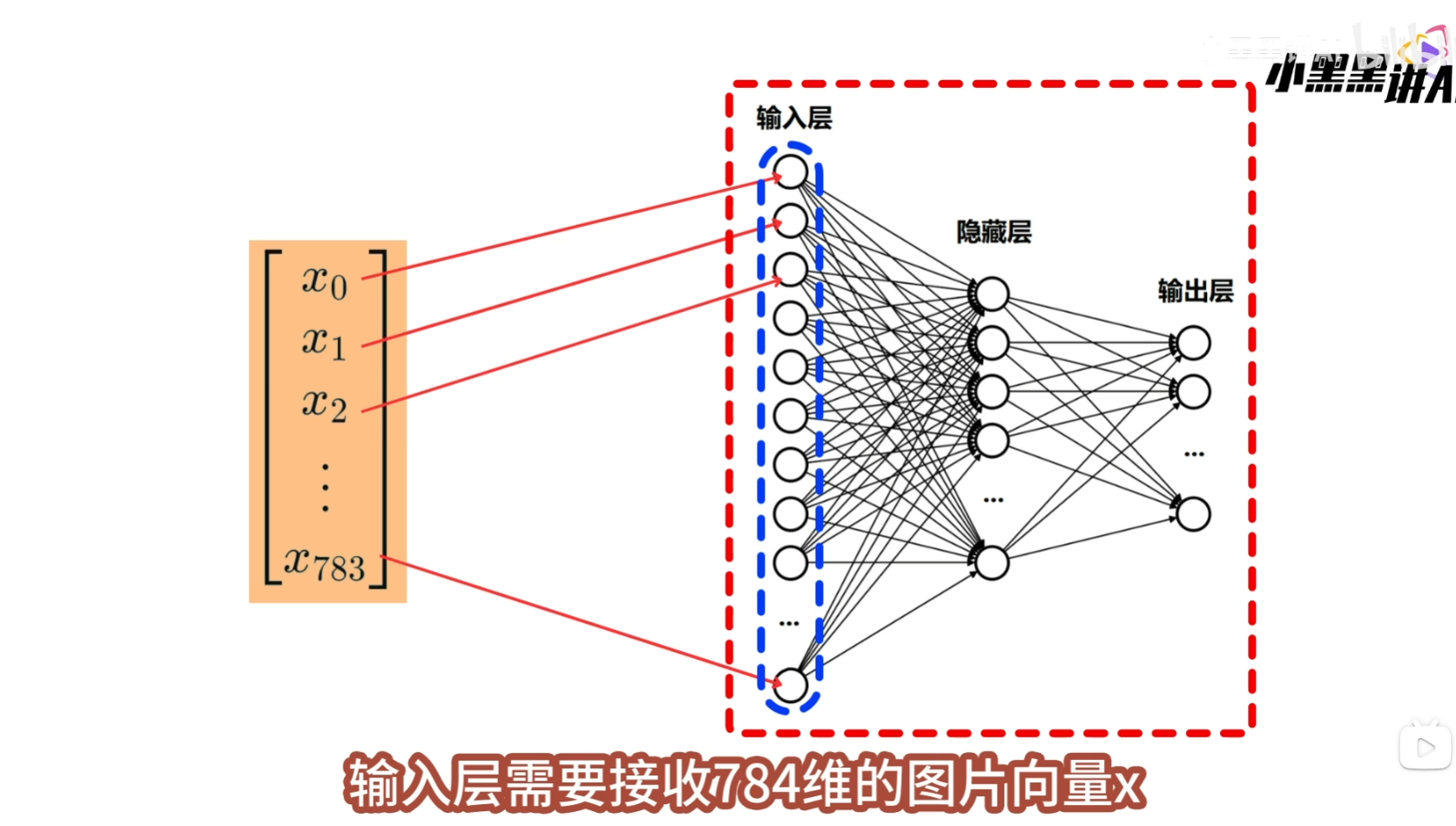 输入向量中的每一个x,都有一个神经元来接收,因此输入层要包含784个神经元
输入向量中的每一个x,都有一个神经元来接收,因此输入层要包含784个神经元 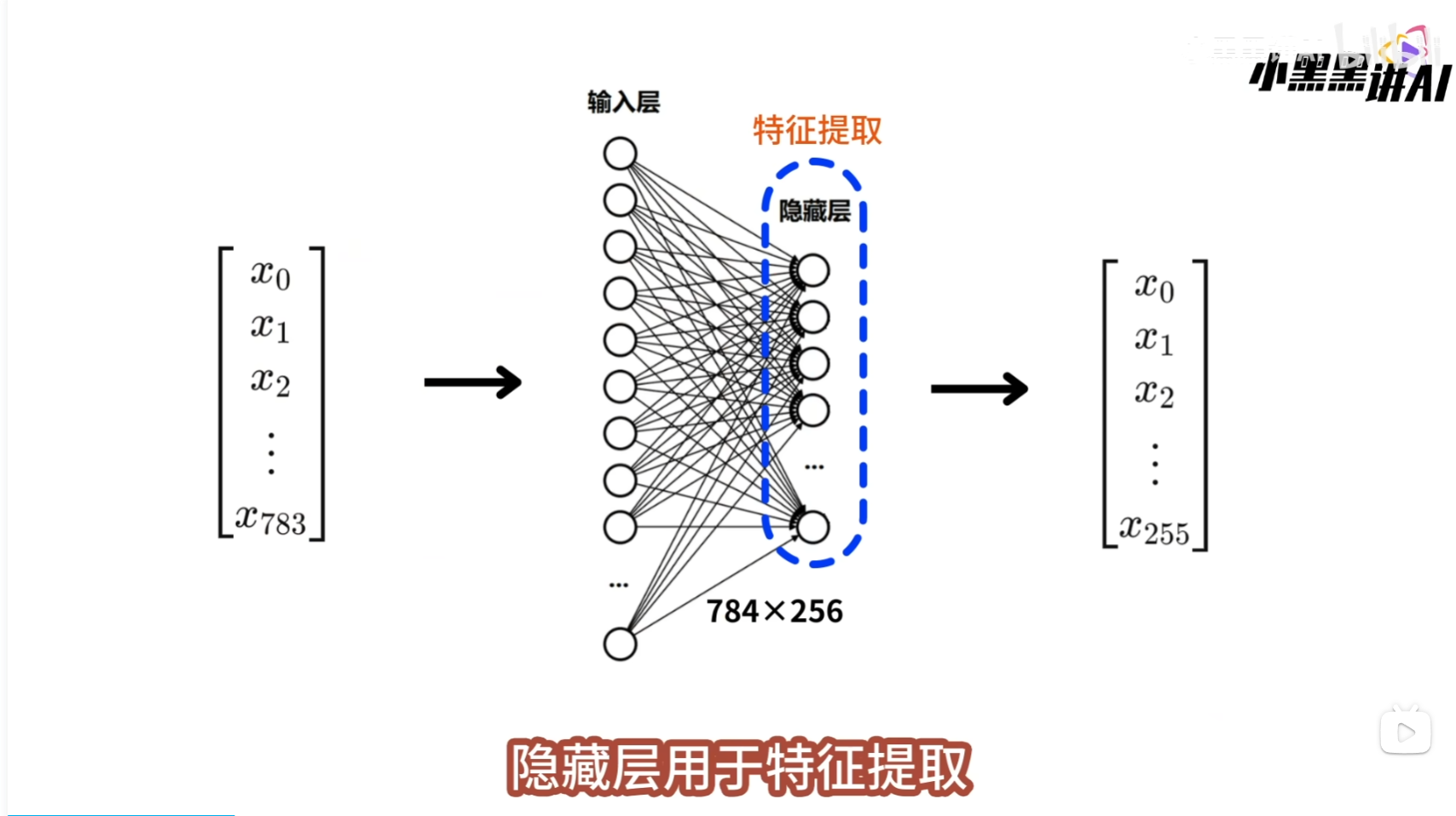 隐藏层用于特征提取,将输入的特征向量,处理为更高级的特征向量,因为这里的处理逻辑不复杂,所以将隐藏层的神经元个数设置为256
隐藏层用于特征提取,将输入的特征向量,处理为更高级的特征向量,因为这里的处理逻辑不复杂,所以将隐藏层的神经元个数设置为256 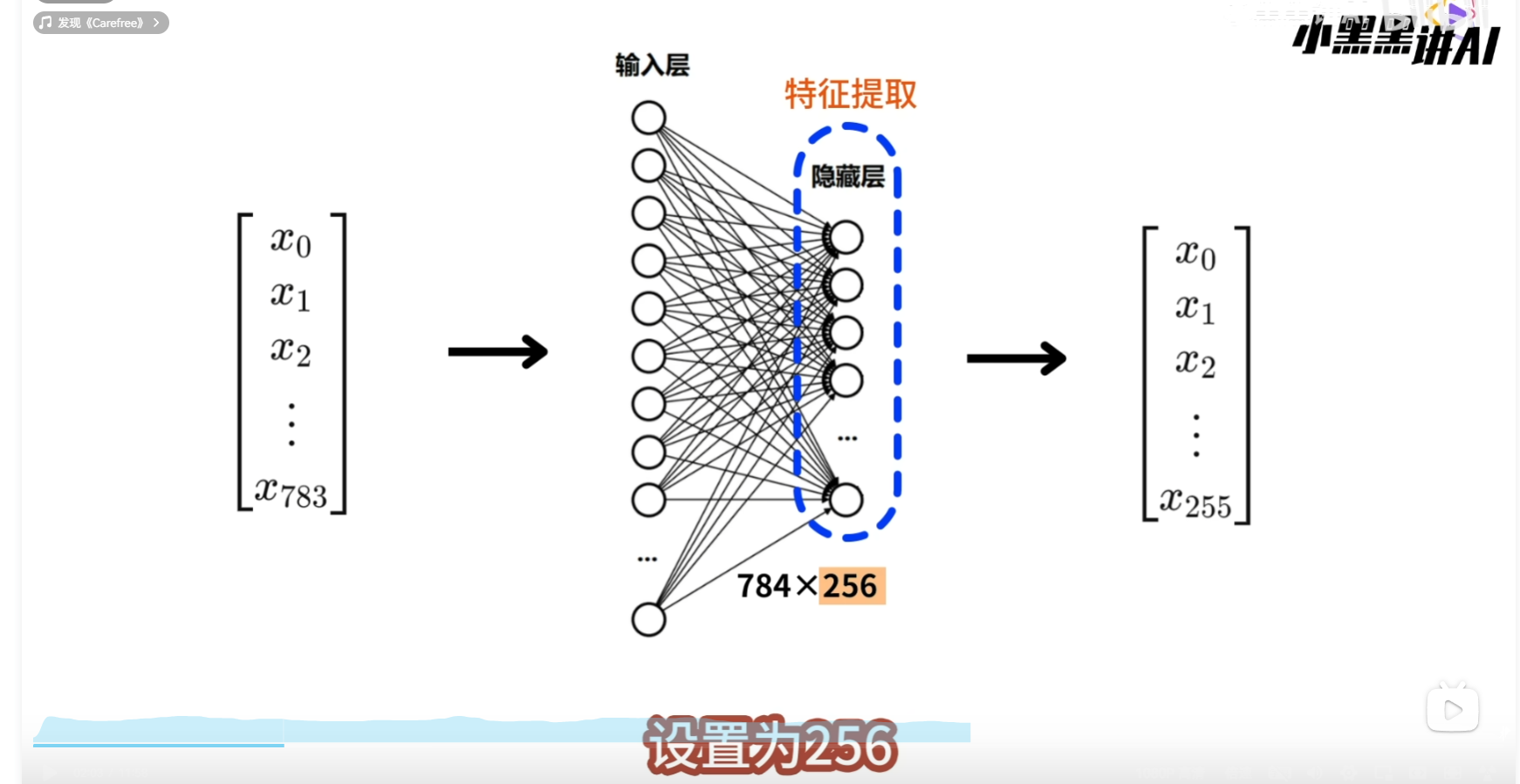 这样输入层和隐藏层之间就会有一个784256大小的线性层,它可以将784维的输入向量,转换为256维的输出向量, 该输出向量会继续向前传播到输出层
这样输入层和隐藏层之间就会有一个784256大小的线性层,它可以将784维的输入向量,转换为256维的输出向量, 该输出向量会继续向前传播到输出层
因为最终要将输入图像识别为0-9,10种可能得数字,因此输出层需要定义10个神经元,对应着这10种数字, 输入向量,经过隐藏层、输出层计算之后,就得到了10维的输出结果,这10维向量,就代表了10个数字的预测得分 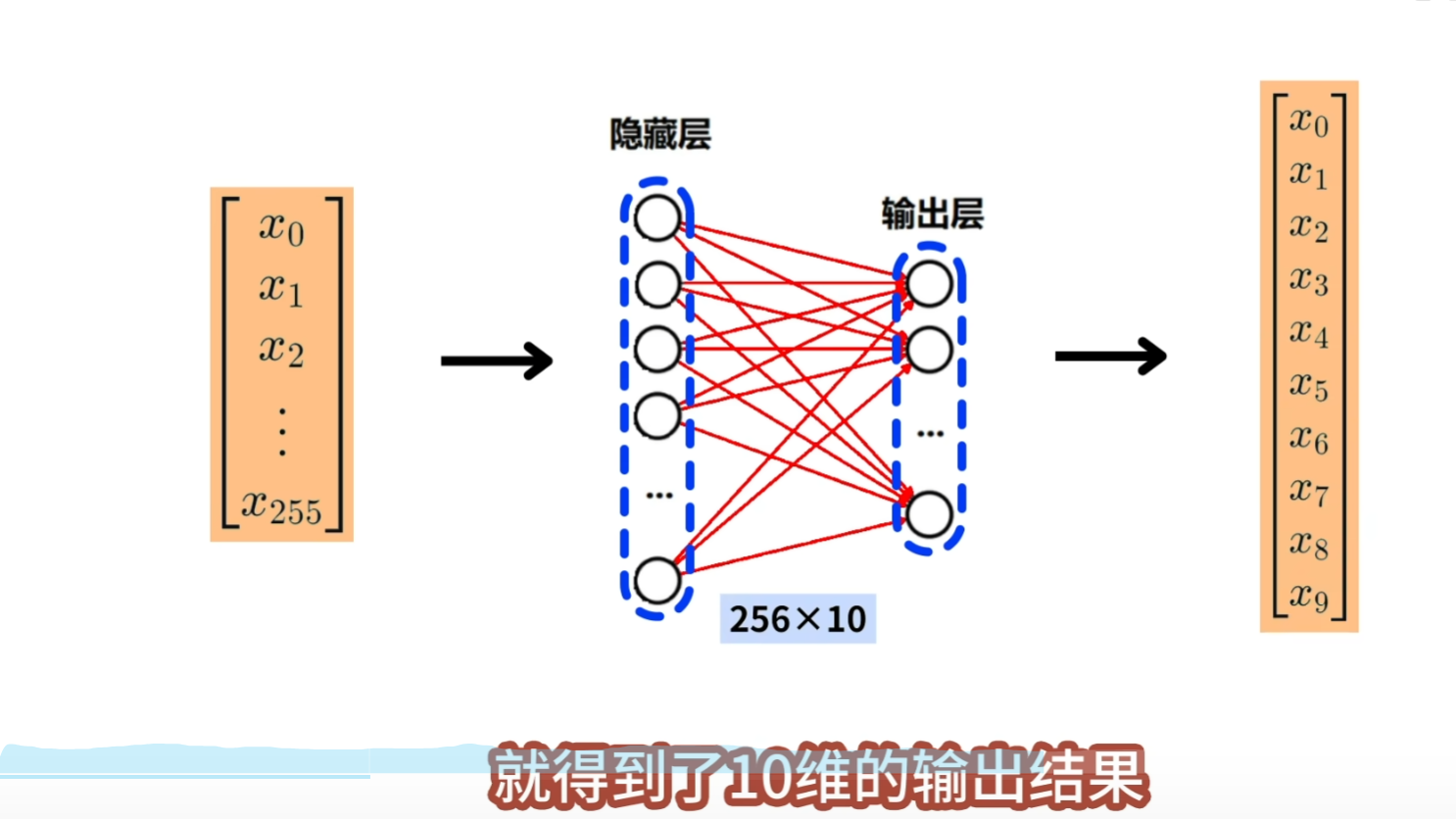 为了继续的到10个数字的预测概率,还需要将输出层的输出,输入到softmax层,softmax层,会将10维的向量,转换为10个概率值,P0到P9,每个概率值都对应一个数字,也就是输入图片是某一个数字的可能性
为了继续的到10个数字的预测概率,还需要将输出层的输出,输入到softmax层,softmax层,会将10维的向量,转换为10个概率值,P0到P9,每个概率值都对应一个数字,也就是输入图片是某一个数字的可能性 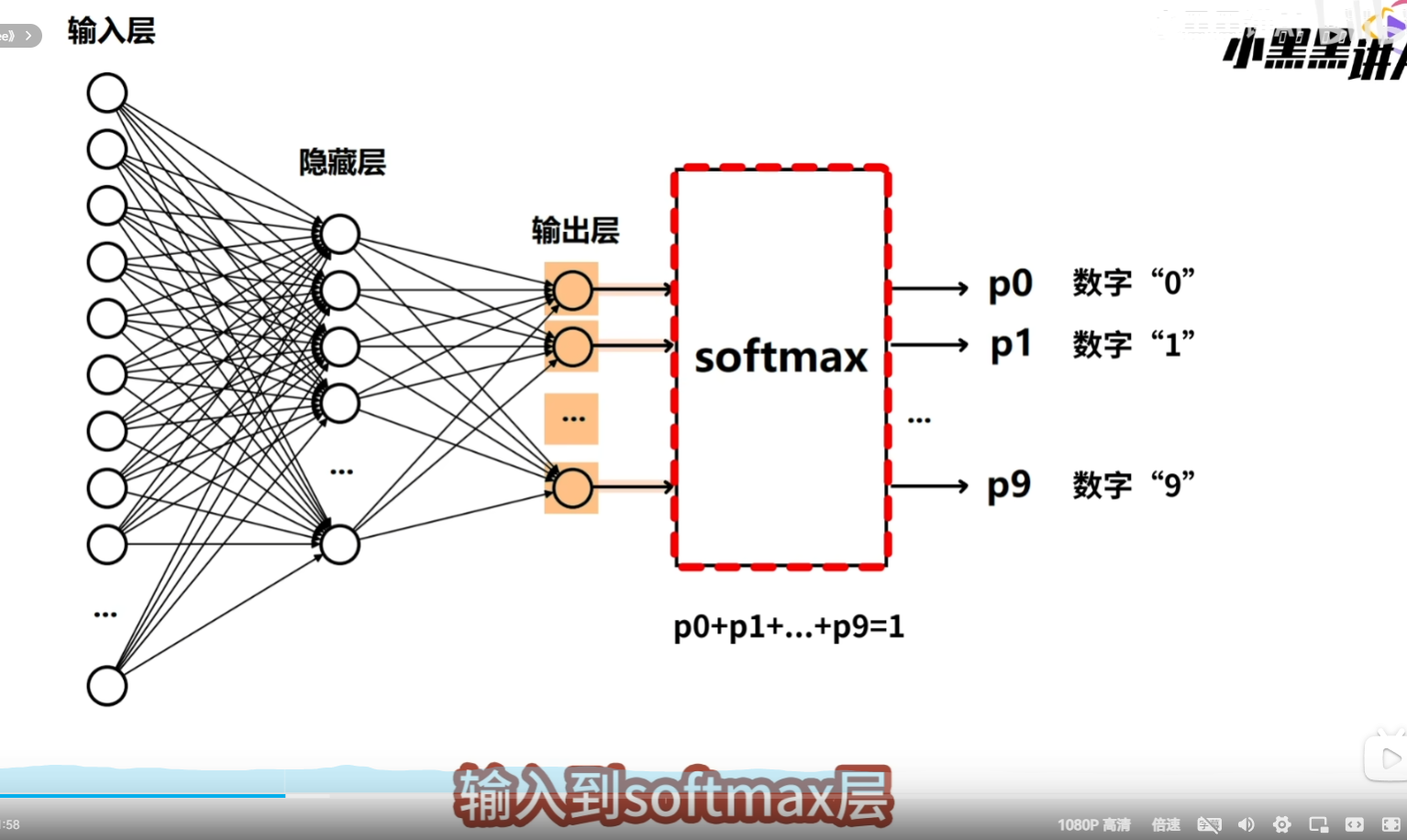
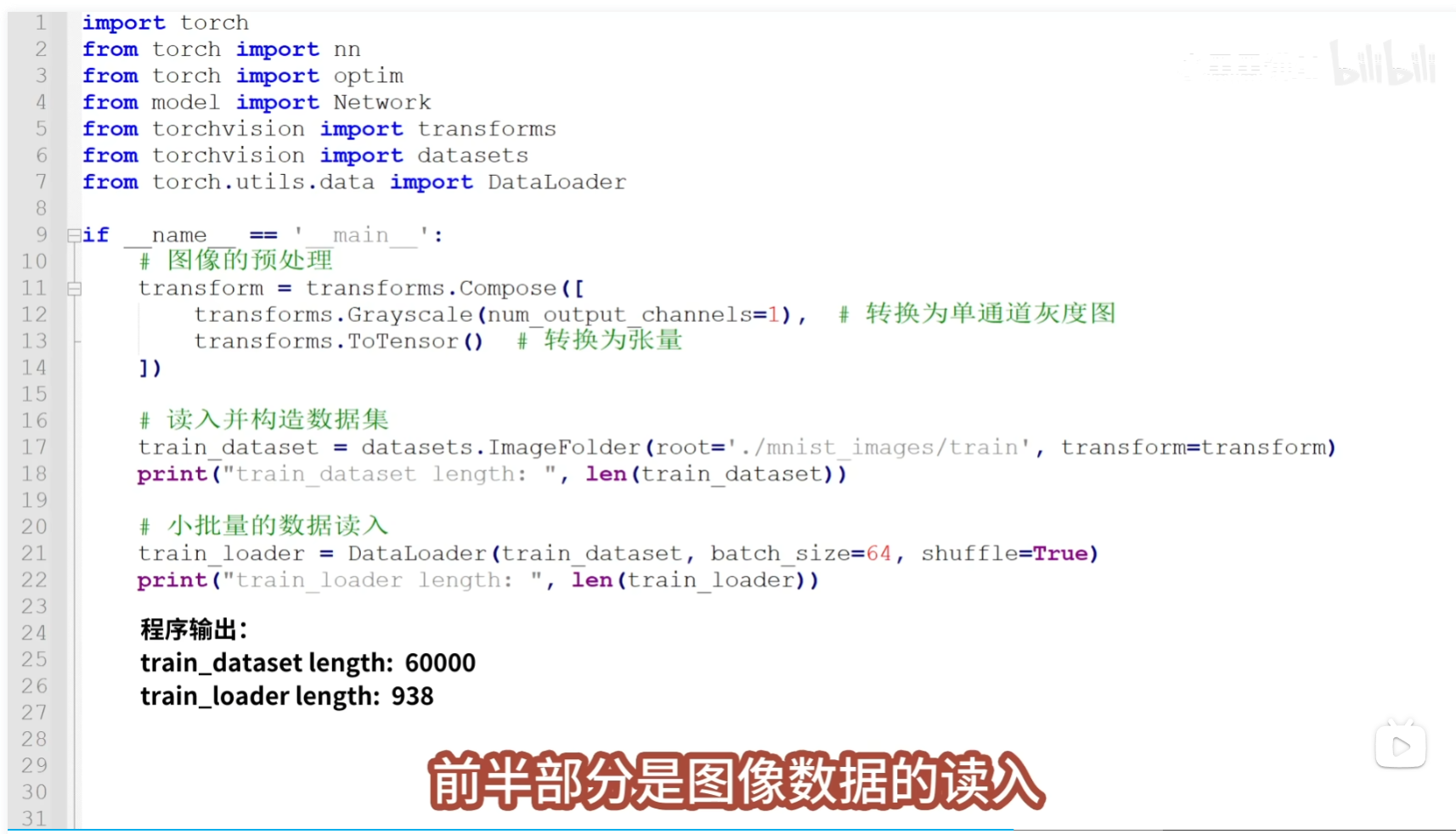
 数据的处理包括三块内容,
数据的处理包括三块内容,

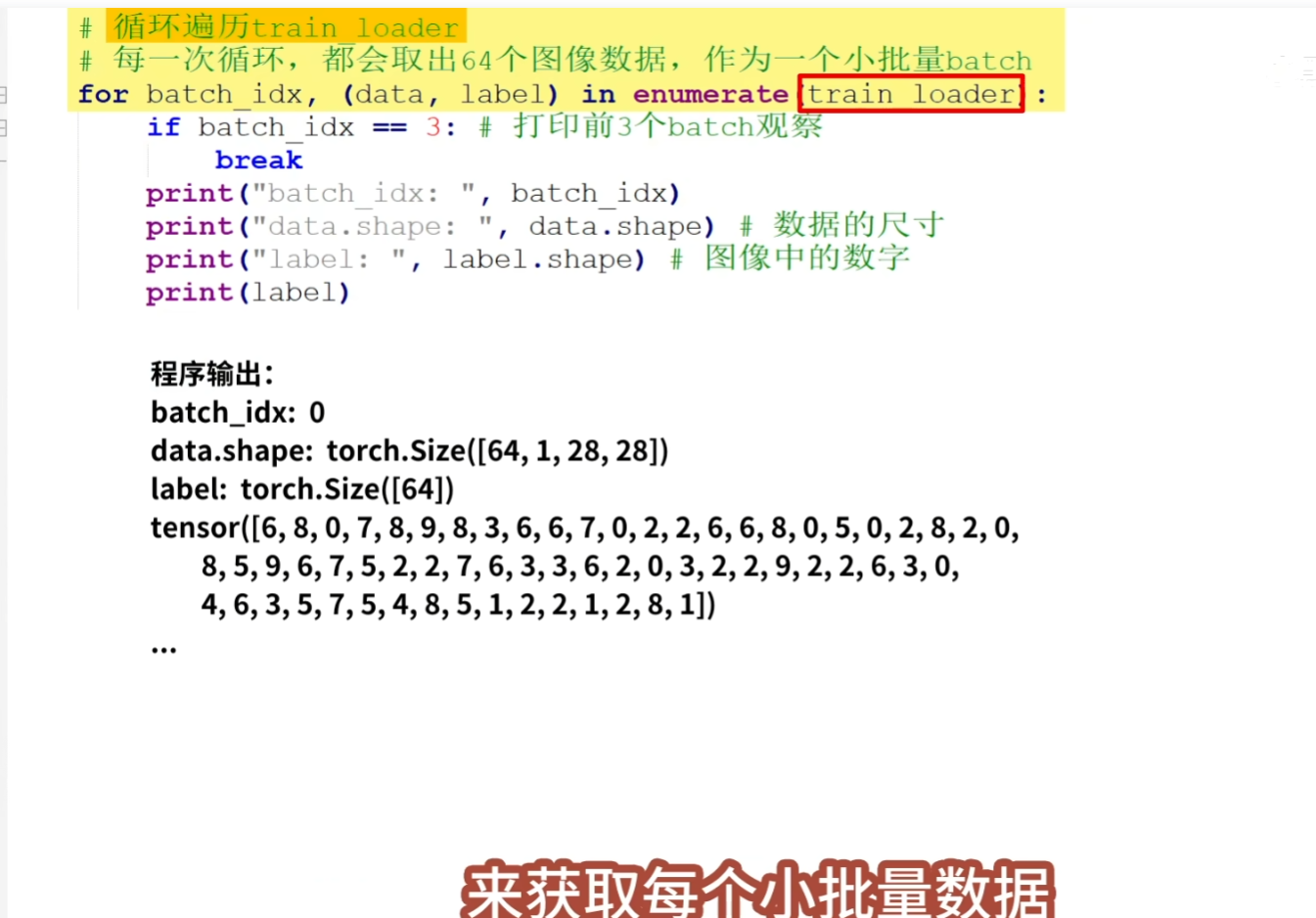 tips:打印出的data.shape为 torch.Size([64,1,28,28]),它表示了每组数据包括64个图像 ,每个图像有1个灰色通道,图像的尺寸为28*28, 打印出的图像的标签label,可以看到64个图片对应的数字,其中保存的数字是0到9,对应了10个数字
tips:打印出的data.shape为 torch.Size([64,1,28,28]),它表示了每组数据包括64个图像 ,每个图像有1个灰色通道,图像的尺寸为28*28, 打印出的图像的标签label,可以看到64个图片对应的数字,其中保存的数字是0到9,对应了10个数字